翻訳メモリは、作成した後も翻訳内容を追加し、蓄積していくことでより効果を得ることができます。
今回は、Trados Studioを使って既存の翻訳メモリに翻訳内容を追加する方法と、その際に気を付けたい設定をご紹介します。
設定によって翻訳メモリに登録される内容が変わるため、自社で翻訳メモリを管理したいとお考えの方は特に、作業前によく確認するようにしてください。
翻訳メモリの登録内容
翻訳メモリには、原文と訳文が対になって登録されています。
翻訳メモリに、すでに登録されている内容と全く同じ原文・訳文のペアがあった場合、翻訳メモリに登録される単位としては1つにまとめられます。
すでに登録されている内容と同じ原文で、訳文のみが異なる場合は、設定によって登録される内容が変わってきます。設定の内容については後ほどご説明します。
翻訳メモリの便利な設定「フィールド」
翻訳メモリには、原文・訳文のペアに加えて、それぞれの文がどこから来たか等の情報を設定することができます。これを「フィールド」といいます。
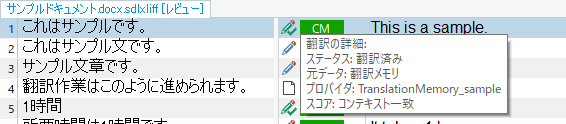
以下は翻訳メモリをTrados Studioで開いたときの画面です。

翻訳メモリごとに、「フィールド」の内容を自由に設定することができます。
今回の例では「ドキュメント」と設定しています。
「値」の内容は文単位で設定することができます。
例えばドキュメントAの内容で翻訳メモリを作成し、そこにドキュメントBの内容を追加する場合、それぞれの登録時に値「A」「B」を設定しておけば、個別の文がどちらのドキュメントに由来するものかを翻訳メモリの画面上で判別することが可能です。
翻訳メモリ更新の基本手順
すでに作成してある翻訳メモリに、新たな翻訳内容を追加することを「翻訳メモリの更新」と呼びます。
翻訳メモリの更新は、Trados Studioを使用すると簡単に行うことができます。
まず、Trados Studio上で、更新したい翻訳メモリがプロジェクトに設定されていることを確認します。

このとき、更新したい翻訳メモリの「更新」チェックボックスにチェックマークを入れておきます。
また、フィールドを使用したい場合は、上部の「設定」からフィールド名を、左側の「更新」から値をそれぞれ設定します。
次に、追加したい翻訳内容が入力されたバイリンガルファイルを選択し、翻訳メモリ作成時と同様に「メインの翻訳メモリを更新」の操作をします。
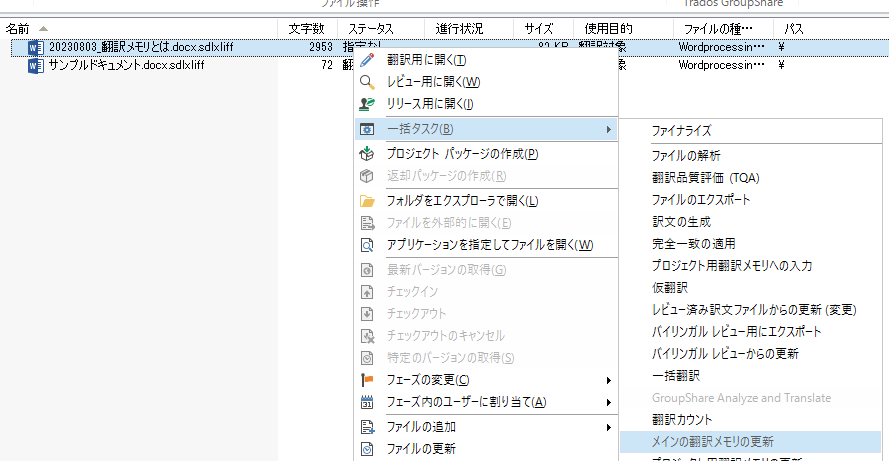
あとは表示されるメッセージに従って操作することで、選択したファイルの翻訳内容を、設定した翻訳メモリに追加することができます。
翻訳メモリ更新時の設定について
翻訳メモリを更新する際に注意が必要な設定について、その違いをご紹介します。
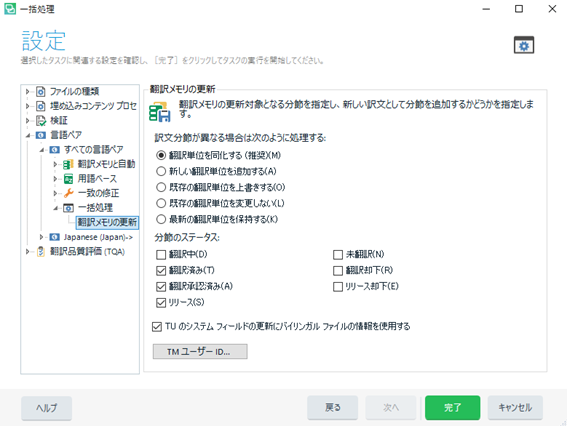
訳文分節が異なる場合は次のように処理する
これは、同じ原文に対して複数種類の訳が存在する場合の処理を設定する項目です。
- 翻訳単位を同化する
より新しい訳文内容が上書きされ、フィールドの値は両方が保持されます。
※常に追加操作を行った方の訳文で上書きされます。
- 新しい翻訳単位を追加する
追加操作を行った内容が、元から登録されている文とは別の新しい文として登録されます。
- 既存の翻訳単位を上書きする
訳文・フィールドともに新しい内容で上書きされます。
- 既存の翻訳単位を変更しない
訳文・フィールドともに元の内容が保持されます。
- 最新の翻訳単位を保持する
より新しい訳文内容が上書きされ、フィールドの値は両方が保持されます。
※最終更新日時によって比較されます。
例えば、和英翻訳で原文が「○」となっており、ドキュメントAでは「OK」、ドキュメントBでは「Supported」と翻訳しているとします。
毎回フィールドにドキュメントの情報を登録していて、ドキュメントAの内容がすでに翻訳メモリに登録されており、ドキュメントBの内容をこれから登録する場合、原文「○」に対する翻訳メモリ更新後の登録内容は以下のようになります。
| 翻訳メモリに登録される訳 | フィールドに登録される内容 | |
| 翻訳単位を同化する | Supported | A/B |
| 新しい翻訳単位を追加する | OK | A |
| Supported | B | |
| 既存の翻訳単位を上書きする | Supported | B |
| 既存の翻訳単位を変更しない | OK | A |
| 最新の翻訳単位を保持する | Supported | A/B |
このように、それぞれの設定によって翻訳メモリに登録される内容が異なり、状況によって適した設定は異なります。
翻訳メモリの内容の違いは、その後の翻訳で使用する際に問題となることが多いため、更新時の設定には注意が必要です。
分節のステータス
これは、翻訳メモリの更新に使用する文を指定するための設定です。
Trados Studioでは、翻訳作業時や訳文内容のチェックを行うときに、文単位でステータスを設定することができます。
このとき設定したステータスを使用し、翻訳メモリに登録する文の範囲を限定することができます。
こちらにチェックが入っていないステータスの文は翻訳メモリに登録されないため、あらかじめバイリンガルファイル上でステータスの状態を確認のうえ、翻訳メモリに登録したいものにはチェックを入れておく必要があります。
| ステータス | 説明 |
| 翻訳中 | 訳文が編集されていますが、翻訳は未完了の状態です。 |
| 翻訳済み | 翻訳が完了し、訳文が確定している状態です。 |
| 翻訳承認済み | 翻訳チェックが完了し、訳文が承認されている状態です。 |
| リリース | 翻訳が承認され、訳文がリリースされている状態です。 |
| 未翻訳 | 訳文がまだ翻訳・編集されていない状態です。 |
| 翻訳却下 | 翻訳チェックの結果、翻訳内容が却下された状態です。 |
| リリース却下 | リリース段階で、翻訳内容が却下された状態です。 |
翻訳メモリ更新を行った後のチェック方法
翻訳メモリを更新する際、選択しているファイルや設定の内容を間違えると、更新漏れの原因となることがあります。
そのため、翻訳メモリの更新を行った後は、更新が正しく完了しているかチェックすることをお勧めします。
翻訳メモリ更新のチェック方法として、翻訳メモリの更新に使用したファイルを対象に、更新後の翻訳メモリを設定して「ファイルの解析」を行う方法があります。
翻訳メモリの更新が正しくされていると、9割以上(ほぼ10割)の内容が「コンテキスト一致」になります。
数パーセントの誤差は問題ないですが、それ以上一致率が下がる場合は翻訳メモリの更新が正しく行われていない可能性があるため、確認が必要です。
まとめ
翻訳メモリは、更新前・更新時に様々な設定をすることができ、大変便利です。
ただし、設定内容を間違えると、意図と違う内容に更新されてしまったり、更新内容に過不足が発生したりする可能性があります。
今回ご紹介した以外にも、翻訳メモリには様々な設定をすることができます。
翻訳メモリは作成時の設定が特に重要になるため、もし迷う場合は専門の翻訳会社に依頼すると安心です。
この記事を書いた人
編集部 Y
この記事をシェアする